算法到底讓我們的資訊環境更閉塞,還是更多元?機器讓推薦和送達更容易了,但我們比以前懂了更多嗎?這個世界本身是否就像是一套算法,隻提供給你需要的東西,這套算法本身是否也在進化?
新聞實驗室的方可成老師在系統性地閱讀了近年來發表在國外一流學術期刊上的研究後發現:使用社交媒體和算法推薦App的人,並沒有明顯出現視野變窄的現象,大多數人閱讀的內容依然有相當的多樣性。
「研究者們選取了21個月的數據。他們將用戶分為兩組,一組是根據算法推薦選擇電影觀看的,叫做「跟隨組」;另一組是不理會算法推薦的電影,叫做「不理會組」。他們發現:算法向「跟隨組」推薦的電影,一直要比向「不理會組」推薦的電影更加多元化。也就是說,根據算法的推薦選擇電影,然後進行打分,其實會讓算法更好地學習到你的喜好,並且給你推薦更多樣的片子;而如果不根據算法的推薦來看電影和打分,反而會讓算法給你推薦更窄的片子。也就是說,在不使用算法推薦的情況下,用戶的視野反而變窄得更快。」
學術的研究結果當然值得參考,不過,如果是針對一個非常極端的內容消費用戶,推薦算法又會帶給他什麼呢?基於一個嚴謹的產品工作者的好奇心和動手欲,以及對這些問題的困惑,我買了一個新手機號,找了一臺沒有裝過今日頭條的廉價安卓測試機,開始了我的「反人類」探索之旅。
我的思路大概是這樣的:在今日頭條上隻關註一個從體量上來說極其小眾的內容領域,逐步成為它的資深內容消費者,然後觀察在這個過程中,頭條會如何投喂我在這個興趣領域的偏好,以及最重要的,最終頭條是否會用這個領域的內容完全淹沒我,讓我只能看到這個領域的內容。

在第一次打開頭條的時候,我是一個空白未登錄的狀態,還沒有任何操作行為或關註任何帳號,頭條推薦頁給我的內容也是比較隨機的,相對以社會新聞和熱點內容為主,其他類內容隨機分布各一條。
所以,我先註冊登錄了一下,然後在推薦內容的「更多」裡,我忽略了頭條置頂給我推薦的娛樂,健康,科技,體育和歷史五大分類,而是直接把列表拉到了最下方,關註了最小眾的「收藏」領域。
同時,我還一次性關註了頭條推薦的20個收藏類的內容創作帳號。收藏這個品類,主要包含的就是文物和古玩類的內容,包括諸如字畫、錢幣和郵票等等之類的都算,而我個人對這個領域基本屬於一無所知的狀態。
關註完20人後,我還做了一件事,就是把收藏標簽移到了最靠近推薦標簽的位置,這樣內容閱讀起來最方便,理論上,這也應該增強了系統判斷給我推薦收藏類內容的權重。

今日頭條App裡默認進入的推薦頁,前三位一般被國家重要新聞給占據了,2條是默認置頂,1條是人民網這樣的官媒發布的熱點新聞,從位置上來說,從第四條開始才算是經過算法推薦展現給你看的內容。
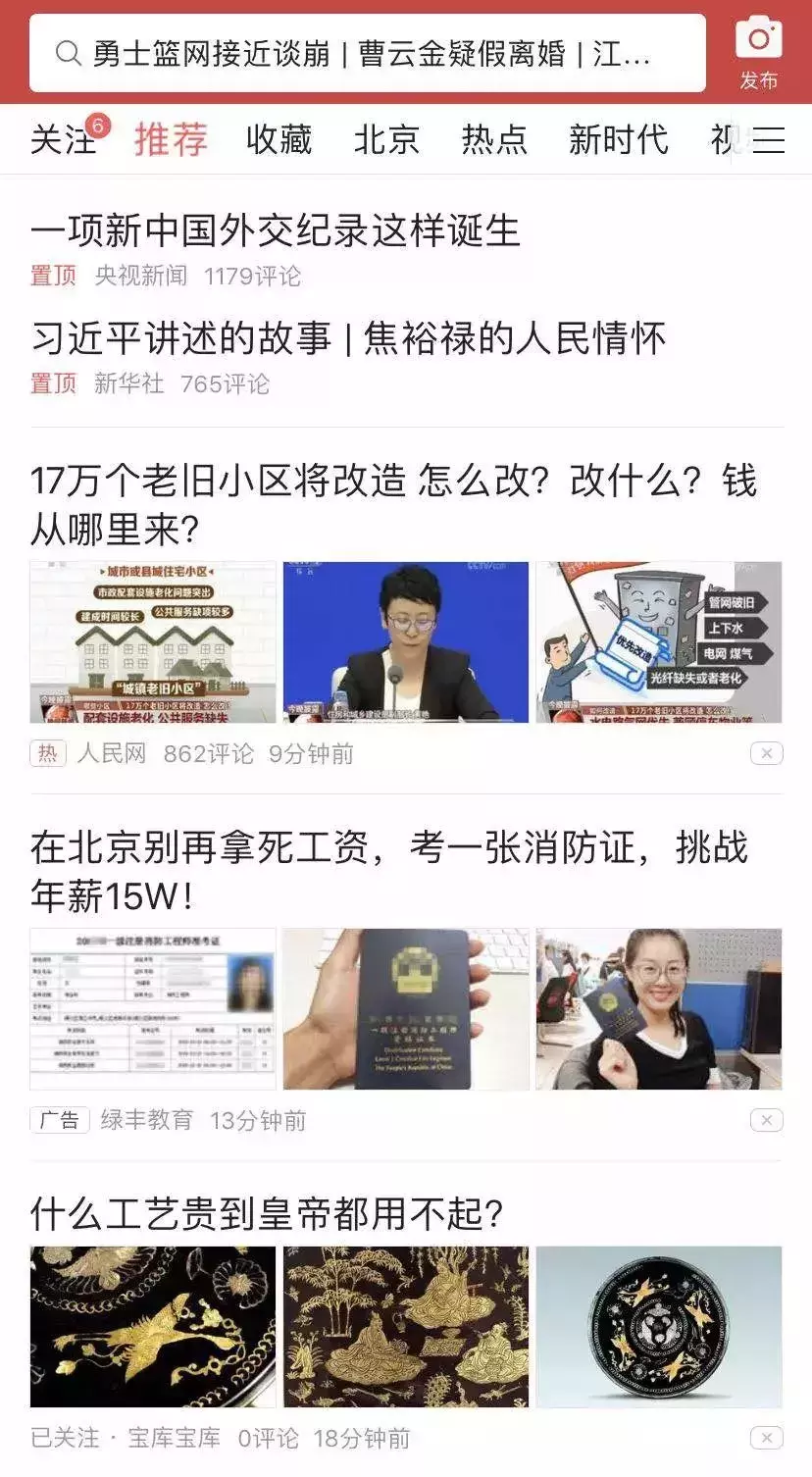
在第一次的刷新中,頭條似乎還沒有給我打上很強的”收藏愛好者「的標簽,整個前10條就一條和收藏相關的,剩下9條裡,除了兩條社會新聞兩條娛樂新聞,其它五類內容各一條。
在我第二次的刷新中,結果依然差不多,收藏只有一條,社會娛樂兩條,其它隨機的五類內容(與第一次的不同)各一條。
第三遍還是如此。
我判斷頭條並不因為我只是關註了一堆收藏類帳號,就判斷我隻對收藏類的內容感興趣了,因為我每次只是在推薦流裡刷下來看標題,還沒有跟任何的收藏文章之間產生互動(轉評讚),也沒有和其他類的內容有過互動,所以我的推薦流裡一直保持了這樣的比例:10%的收藏類內容+不斷更換的其它類內容。
不過雖然內容流裡收藏內容不多,但是在「他們也在用頭條的」橫向推人的流裡,出現了這麼一個情況,左右滑動的區域內一共可以顯示10個帳號,其中有9個是收藏類帳號。
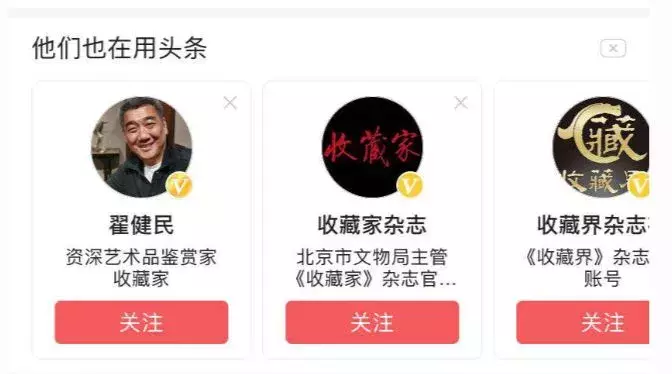
從這裡也可以看出,對於薦人和薦內容,頭條可能是採用分開的兩套策略。我猜測,帳號推薦上,頭條希望快速收攏以獲取你的關註關係,增強它App內部的連接,所以直接給你推已經關註過的同類帳號,但內容推薦上,頭條需要你進一步有更多反饋數據後,才會逐步讓某一類內容更多占據你的推薦流。
於是從新的一次下拉刷新開始,我做了這麼一件事:對頭條在推薦流裡給我的每一條收藏類內容,都點擊進入文章,慢慢再慢慢地下拉到底部(當然我一個字也沒看進去),然後點讚,點收藏,評論(一般就幾個字:真棒,好喜歡,不錯,之類的)。
大概從第五次刷新開始,收藏類內容的比例終於開始變多(我為什麼要說終於),同時,推薦流裡出現我未關註的收藏類帳號發的內容,我會在內容互動後一並關註作者。
大概從第8次開始,收藏類內容達到了30%的比例,而同時推薦流裡還開始出現人文和歷史類的內容。
我判斷這兩類內容會出現,是基於算法的「協同過濾」,因為想精通收藏的領域背後需要非常了解文化和歷史類的知識,這樣才有助於判斷各種文物和古玩的價值,所以一個「收藏愛好者」必然也得看文化和歷史的內容。
(解釋一下:常見的協同過濾算法有兩種,一種是基於用戶的(user-based),也即計算用戶之間的相似性,如果A和B的興趣相近,那麼A喜歡的電影,B也很有可能喜歡。另一種是基於物品的(item-based),也即計算物品之間的相似性,如果電影C和電影D很相似,那麼喜歡電影C的人,可能也會喜歡電影D。)
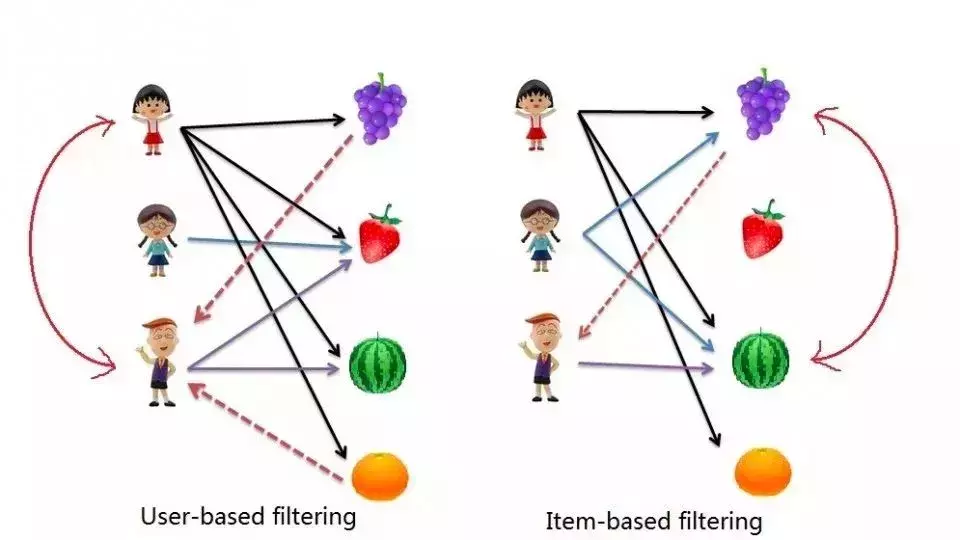
這裡可以看出,盡管收藏類內容如此小眾,但頭條的算法依然找到了一批和我類似的「收藏愛好者」,並把他們同樣愛看的「人文和歷史」內容推到了我的面前(盡管比例還很小,各一條)。
(不過雖然關註了收藏的人,很大機率會關註文化和歷史類的內容,但反之貌似大機率未必,文化和歷史愛好者未必對古玩錢幣什麼的有興趣。但是對於頭條的機器算法來說,更好的推薦策略肯定是,給一個對文化和歷史有興趣標簽的用戶在推薦流裡偶爾夾雜一條收藏類內容,視乎其反饋來決定是否推薦更多。頭條算法架構師曹歡歡曾表示:「我們會留一部分比例流量,探索用戶的興趣,例如每幾刷,或有一刷的位置就是探索用戶的興趣,推薦一些模型不確認用戶是不是感興趣,但是模型想探索一下,會有一些這樣的流量。」)
說回我的實驗,我在刷新後「對每條收藏類內容給予重度反饋然後忽略其它一切內容」的行為很快獲得了算法的高度重視,收藏類內容從比例來看快速升高,最多的時候達到了每10條裡有6條收藏強相關的內容,大概1-2條人文或者歷史的內容,剩下2條還是社會熱點和娛樂新聞。
而且一般在前三條裡,必有一條是直接關註帳號發的收藏內容,剩下兩條可能是相關人文歷史領域的內容或者還未關註的帳號發的收藏類內容。
最後,我把這個「極端收藏愛好者」的身份堅持了兩周左右,每天重復十幾次到數十次不等的刷新,然後隻對收藏類內容進行點擊閱讀、評論、點讚、收藏和關註。
不過,最終頭條給我的推薦比例卻沒有繼續增加,前10條裡,除了廣告比例提高(可能是覺得老用戶更能忍?),最多的時候還是5-6條收藏類相關內容,少的時候2-4條。其中,必有2條以上是收藏類強相關的內容(直接探討收藏物本身),1-2兩條收藏弱相關的文章(或我關註的收藏領域帳號發布的其它領域內容),以及1-2條文化和歷史強相關內容,而剩下還有4-6條則都是非收藏相關的內容。
看起來,推薦算法並不會出現10條裡9條都是收藏類內容的情況。經過這個十分極端(真實用戶不可能隻在新聞資訊App裡盯著收藏內容不放)但其實並不麻煩的實驗之後,我整體的感受有以下幾點:
1、推薦算法在做的並不是以某一條內容去壓中你的興趣,而是以「組」為單位(10-20條)來測試你(身份標簽)、你可能會喜歡的內容(興趣標簽)和你當下的狀態(環境標簽),命不命中是一個機率遊戲;因為要條條命中、甚至單條命中其實很困難,但以組為單位去看壓中過(1-2條)的機率,很有可能在90%以上。
2、所以純以興趣推薦為基礎的產品,最難的是用戶前三次使用的時候,可能流失率很高、印象很差,後面基於用戶在內容消費上的需求和行為為基礎,使用大機率會越來越順。
3、資訊推薦類平臺沒可能最終隻提供特定某一類內容給你看,因為這本質並不利於它自己的日活和時長,當你的今日頭條完全變成「收藏頭條」後,也是一個用戶離開的時候。
4、例如頭條架構師曹歡歡曾提到:「聰明算法工程師都不希望自己的用戶興趣窄化,就像沒有一個商場的經理,希望顧客每一次來到商場都隻關註同一類別的商品。商場經理都希望顧客關註盡可能多的產品品類,算法工程師也希望用戶盡可能的拓展自己的興趣。」
「一個喜歡鞋子的用戶,假如每次來商場都能快速買到自己喜歡的鞋子,用戶的單次消費就很開心,但最終用戶會減少來這個商場的消費次數(包括每次來商場逛的「用戶時長),除非他又產生了買鞋子的需求。要把用戶長期留存下來,就要穿透他的興趣,拓展他的視野,讓他衣服、飲食、看電影這些消費,都在商場裡完成。」
5、要注意的是,傳統上我們經常提到的「資訊繭房」並不是一種理論(theory),而是一種假設(hypothesis),至今仍未得到數據量化和案例的證明。學術上更常見的是概念是「資訊回音室(echo chamber)」和「過濾氣泡(filter bubble)」:人們在某些社交和新聞類產品裡更容易聽到回聲和資訊被過濾,但這不是類似繭房的完全束縛,也不代表「一個人的資訊獲取不再多元」或「意見被單一來源的資訊左右」。
6、相對算法推薦,過去報紙、雜誌和入口網站更有可能造成「資訊繭房」一些,因為他們的內容本質上是由一群天天泡在一起相互影響的編輯們推薦給你的。而朋友圈的資訊可能是最容易造成「資訊繭房」的,前提是你隻通過朋友來獲得資訊和看法,但這個現象本質上這也只能算是「社交偏食」而已,自古以來人總傾向於和自己喜歡的人多打交道和聊天;
7、從認知心理學的角度來說,人類大眾一直難以避免的是「確認偏見」(confirmation bias),也即更願意相信自己已經認同的內容。
如果你隻和自己聊得來的人交朋友和聊天,且只看自己認同的內容,堅持相當長一段時間後(封閉環境不被打破),那麼他還真有可能無限接近資訊繭房狀態,只不過這個繭房是一種作繭自縛。
但這個時候,推薦算法反而是可以幫你進行繭房穿透的武器之一,並對抗因為年歲增長而導致的好奇心的衰減。
例如在我作為一個「極致的收藏愛好者」的數據反饋之下,頭條並未給我推的全是收藏類內容,還是保持了社會熱點新聞的比例,然後漸漸為我找到了文化和歷史內容,並在後期持續測試我的興趣邊界,不斷找到了可能和我作為一個「收藏重度愛好者的用戶畫像」相匹配的內容(對收集有歷史價值的物品、及其相關交易極度感興趣、大機率是男性、注重傳統文化、年齡在估計在40歲以上),給我推薦了財經、科學、釣魚和養生類相關的內容。
8、文初提到的方可成的學術研究裡,還說到另一個原因解釋了人們為什麼會對「資訊繭房」信以為真,那是因為我們的「心口不一」:人們會向研究人員過度報告自己常看的一些媒體(通常是和自己的態度相近的媒體),而沒有報告另一些自己也確實看過的媒體(和自己的意見相反的媒體)。例如你是一個美國政治自由派,你平常可能既看自由派的媒體,也接觸到了保守派的媒體,但是在向研究人員報告自己的媒體消費情況時,你隻報告了自由派媒體,而隱藏了自己消費的保守派媒體。
人們喜歡宣稱和堅持自己的人設,因此有時很難正確回憶自己的行為,造成了類似「幸存者偏差「的效應。但整個世界其實一直在滾滾向著多元化的一面發展,用戶和內容在多元化,算法其實也在多元化。


































.png)
