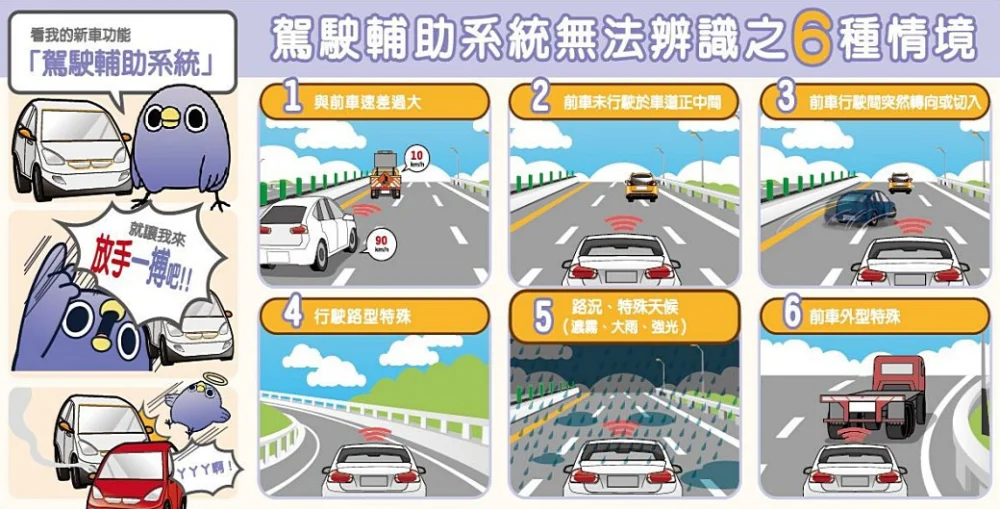




生活

台南轉播應援2026WBC世棒經典賽 邀請市民為台灣加油
記者吳順永/台南報導「2026 WBC世界棒球經典賽」將於3月5日於日本東京巨蛋熱血開打,為與市民共同感受國際棒球賽事的魅力,臺南市政府體育局將於3月5日至3月8日辦理「2026WBC世界棒球經典賽熱血應援派對」,活動將於永華市政中心西側廣 …




健康

「會走路的肺炎」變身「狂奔的肺炎」! 一家七口5人B流+黴漿菌肺炎「包牌」 嘆:買彩券都沒這麼好運
記者林重鎣/台中報導年假甫結束,護理師「阿雲」剛開工不久,就出現狂咳、發燒、全身痠痛等症狀,家中七口人更有4人上演同樣戲碼,連9個月大女嬰咳到「連牛奶都不喝」,經檢查發現原來是同時感染B型流感與黴漿菌肺炎,形成雙重夾擊,導致病情加劇,醫師呼 …
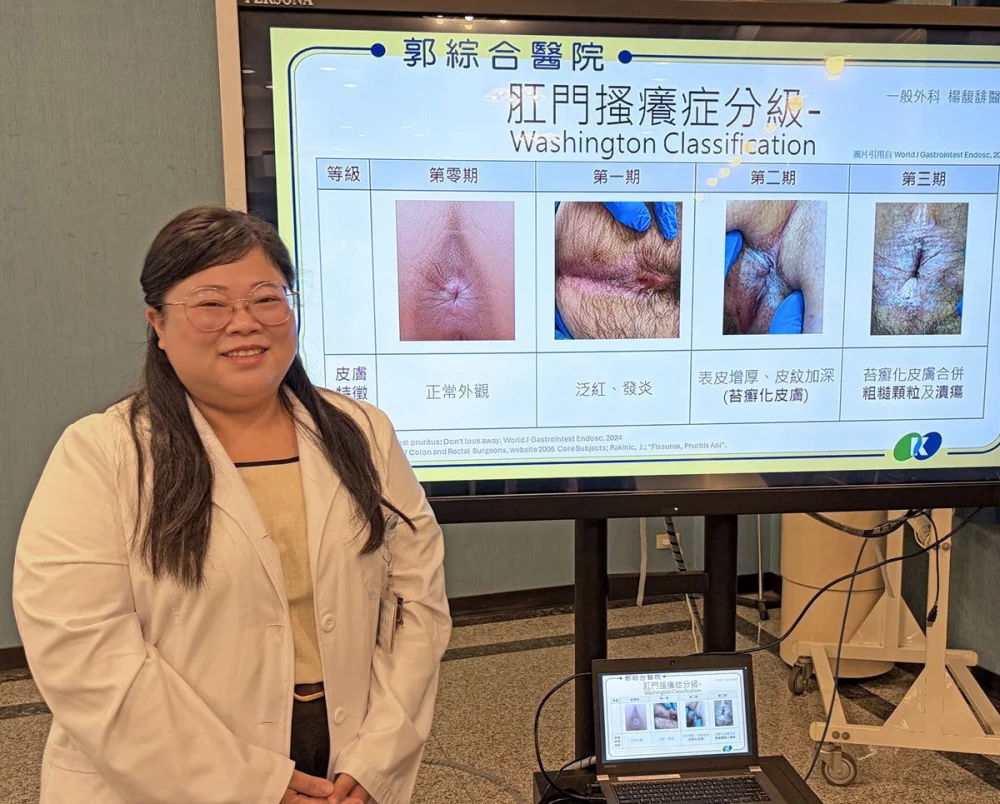



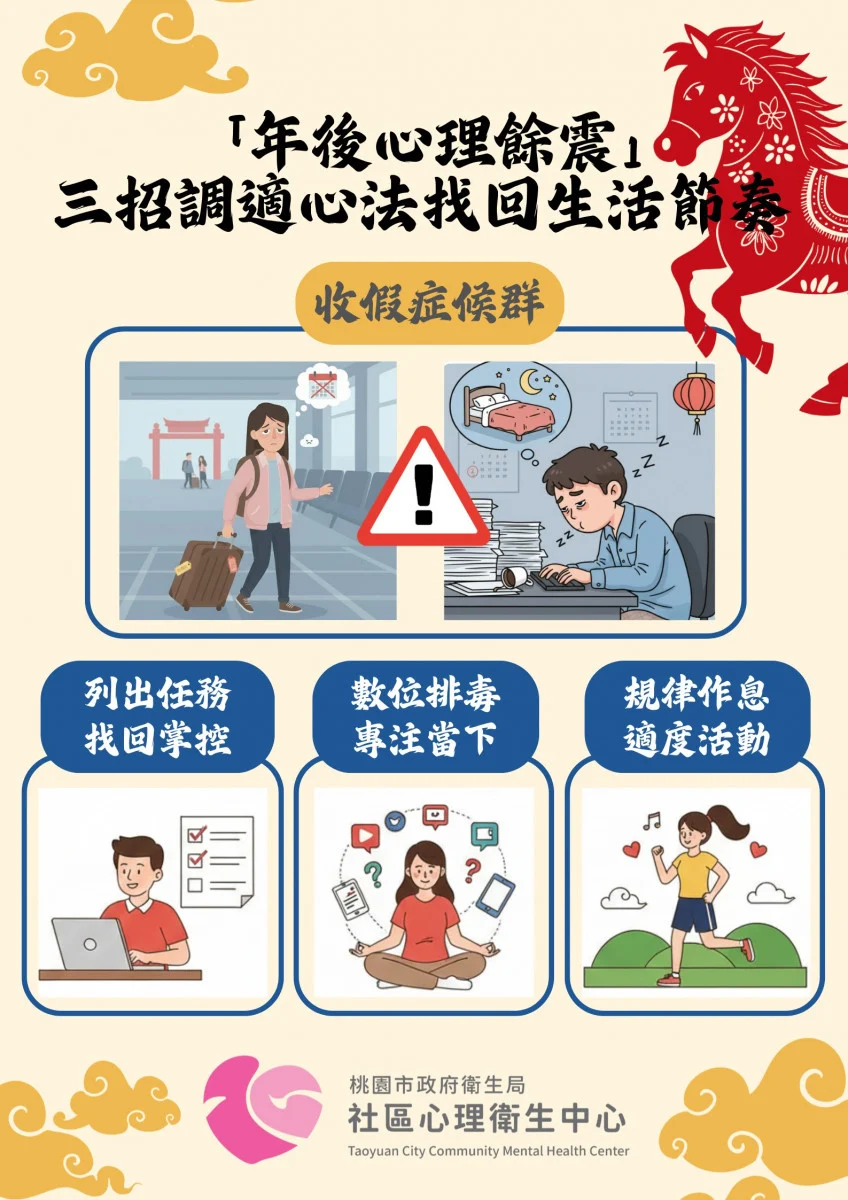
旅遊

新北「微笑近山走3徑」3/14登場 走訪深坑茶山古道聽音樂品茶香
記者黃村杉/新北報導新北市政府觀光旅遊局將於 115 年 3 月 14 日(六)在深坑茶山古道「林家草厝」,舉辦「微笑近山走3徑」山林展演主題活動,結合茶文化與音樂展演及山林健走,邀請民眾走入山林、回望茶路,在自然與人文交織的場域中,體驗放 …




政經

主持將官晉任授階 賴清德勉國軍加速建構不對稱戰力
政治中心/綜合報導(圖/總統府提供)總統賴清德今(25)日主持「中華民國115年3月份將官晉任授階典禮」時表示,面對快速變動的區域情勢與複合式威脅,國軍應持續邁向「新訓練、新思維、新裝備、新科技」的目標,結合科技、制度創新與「全社會防衛韌性 …











之《2026永續年鑑》(The_Sustainability_Yearbook_2026)橘子集團蟬聯互動媒體娛樂業全球同業中名列第三名.webp)
