





生活

運動×文化×專業實作 南港高工打造深度台日校園交流
地方中心/台北報導(圖/台北市府教育局)為深化國際教育交流、拓展學生全球視野,台北市立南港高工日前熱情接待來自日本的大阪府立枚方高等學校,共計335位師生蒞校參訪交流,透過多元體驗課程與互動學習,展現技職教育接軌國際的豐碩成果。活動以溫馨隆 …





健康
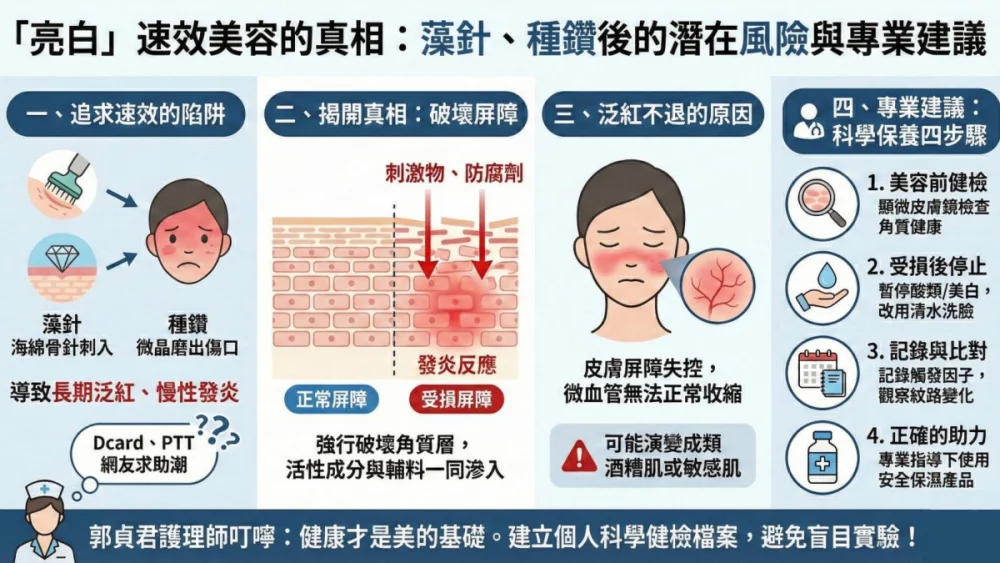
「亮白」背後是重生還是慢性受傷? 資深護理師揭開藻針、種鑽後的泛紅真相
記者楊博喻/綜合報導近年「藻針」與「種鑽」美容措施因強調速效而盛行,卻導致許多愛美者出現長期泛紅與慢性發炎。中華國民美容醫學會美容醫學小組召集委員、資深護理師郭貞君提醒,這類物理性換膚若操作不當會破壞皮膚屏障,導致長期泛紅與慢性發炎。接下來 …



旅遊

北投陽明山雙花季限時綻放至3/15 台版富良野與粉紅櫻花海打造最強春日一日遊
記者楊博喻/旅遊報導當冬日的冷冽逐漸退去,台北的街頭正悄悄換上最絢爛的春裝。如果您也渴望一場逃離塵囂的輕旅行,那麼今年的「台北雙花季」絕對是送給自己最好的春日禮物。從北投的繽紛坡地到陽明山的雲霧櫻林,這不僅是視覺的饗宴,更是一次與心靈對話的 …




政經

遠離台首例疫情逾3個月 農業部:已向WOAH遞非洲豬瘟自我聲明非疫區申請
政治中心/綜合報導台灣養豬場業者飼養豬隻。(圖/資料照片,圖源:行政院農業部畜牧司)台中市梧棲區一間養豬場,去(2025)年10月中被發現斃死豬上,驗出台灣首例非洲豬瘟疫情,後續引發中央下令全國豬隻禁運禁宰15天,引起畜牧業、餐飲業、零售業 …














