為青埔核心交通樞紐,串聯雙北與桃園、新竹生活圈,奠定區域發展基礎。(圖/21世紀不動產提供).webp)


_0.webp)


生活
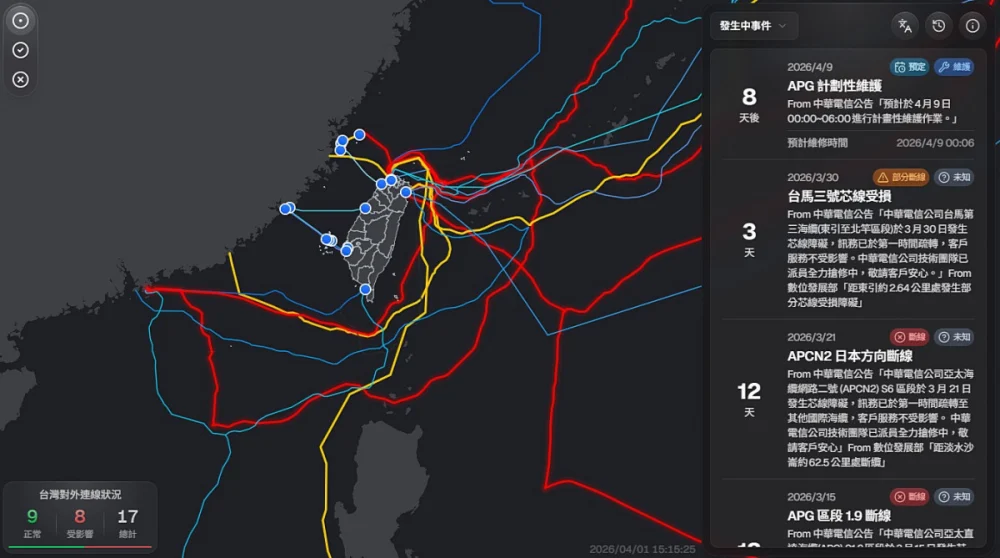
傳臺馬三號東引段海纜斷線 數發部澄清:部分芯線受損,未影響正常通訊
生活中心/綜合報導台灣海纜動態地圖。(圖/翻攝自台灣海纜動態地圖網站即時資訊https://smc.peering.tw/)近年台灣與離島、海外的海底通訊電纜,頻傳斷裂事故。除了線材老化破損、海洋生物啃咬…等既有原由外,近年傳出中國疑似利用 …





健康
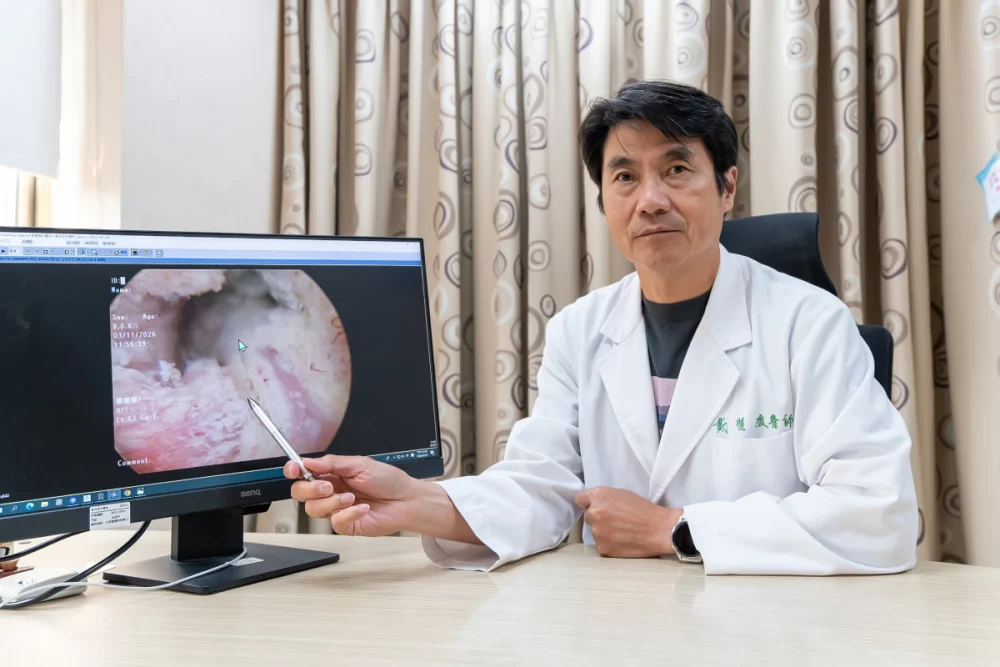
揮別攝護腺癌 「海扶刀」精準定位消融癌細胞
記者季大仁/新竹報導東元醫院泌尿外科戴順慶醫師利用「海扶刀(HIFU)高強度聚焦超音波微創手術」幫助多名攝護腺癌病人,揮別早期攝護腺癌症陰霾。攝護腺癌呈現年輕化,正值壯年的病人而言,如何在根除癌症的同時保留生活品質是關鍵。東元綜合醫院泌尿外 …




旅遊

療癒旅遊正夯! 潘若迪領軍秧悦美地「國際健康療癒節」
生活中心/綜合報導 跟著潘若迪在花蓮山林環抱中動起來,於秧悦美地度假酒店找回身心平衡的節奏。 花蓮秧悦美地打造森林與香草療癒旅行 近年來,療癒旅遊已成為全球旅遊趨勢。越來越多旅人選擇在旅行中放慢步調,透過運動、自然與內在覺察,達到壓力釋放與 …




政經

參選台北市長? 沈伯洋鬆口:若黨需要「我一定配合」
政治中心/綜合報導(圖/翻攝YOUTUBE)九合一地方大選年底登場,民進黨首都人選遲未出爐。原本黨內呼聲極高的行政院副院長鄭麗君參戰意願不高,傳近日黨高層改啟動「B計畫」,盼民進黨立委沈伯洋披掛上陣。沈伯洋今天接受廣播節目鬆口,若黨中央選對 …













