記者張文熹/彰化報導
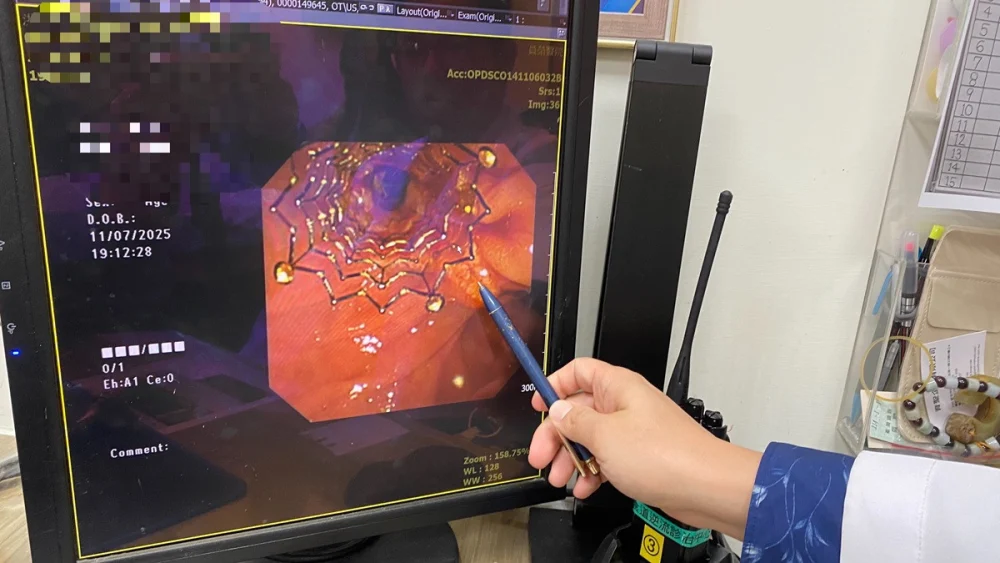
一名70多歲患者因腹痛、發燒,到員榮醫療體系員榮醫院就診,胃腸肝膽科醫師曾宇辰發現患者先前在其他醫院置放的膽道塑膠支架被膽汁阻塞,造成肝內膽管擴張。手術團隊移除塑膠支架後,以精準技術導管通過狹窄處,順利完成置放金屬膽道支架,讓膽汁排出,患者術後恢復良好。
曾宇辰醫師指出,患者因膽道腫瘤數月前在他院接受手術治療,術後併發膽道狹窄,曾接受逆行性胰膽管鏡(ERCP)並置放塑膠支架。日常患者因發燒腹痛,家人將她送到員榮醫院員生院區急診,收治住院,住院期間檢查顯示,患者肝功能異常,黃疸膽道指數亦明顯升高。經醫療團隊與患者溝通討論後,符合惡性腫瘤適應症,曾宇辰主治醫師建議將原有塑膠支架更換為金屬支架,以改善膽汁引流情況,降低再次阻塞風險。
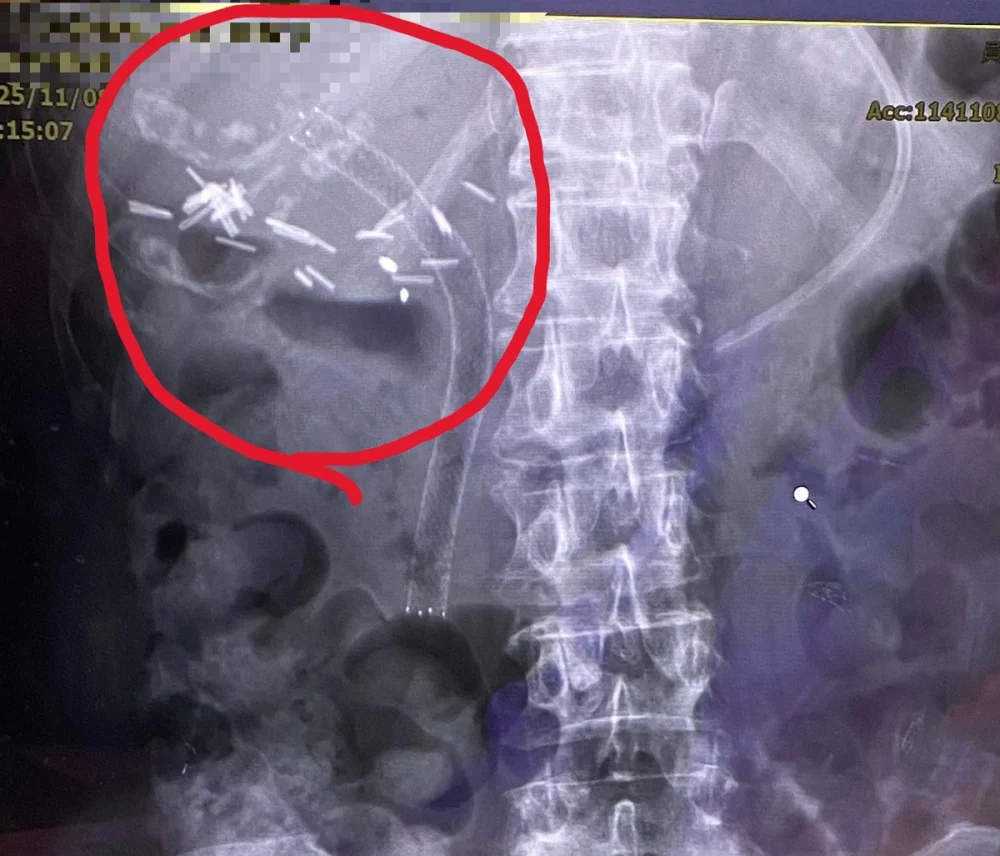
經由逆行性胰膽管鏡檢查發現,原有塑膠支架已完全被膽汁阻塞,使肝內膽管擴張。手術團隊以精準技術使導管通過狹窄處先移除塑膠支架後,再置放金屬膽道支架,讓膽汁得以順利排出。術後X光影像顯示,金屬支架位置良好,膽汁引流恢復正常。患者術後症狀明顯改善,包括腹痛、噁心及黃疸皆逐步消退,肝功能指數亦恢復正常。

曾醫師指出,膽道支架依材質區分為塑膠與金屬兩類,適應症及使用期限不同。塑膠支架約3至6個月需更換,有支架阻塞的問題,金屬支架通暢時間較長、管徑大、抗腫瘤壓迫能力強,可維持一年或一年以上,如罹患惡性膽道或胰臟腫瘤患者,健保有給付,優點在能降低支架阻塞及減少反覆置換的醫療負擔,大幅提升生活品質。
這名患者置換支架後恢復順利,目前在門診定期追蹤,沒有再出現黃疸、腹痛或感染情形。曾醫師提醒民眾,若曾接受膽道手術或發生膽道狹窄,出現黃疸、眼白變黃、持續性腹痛或右上腹悶痛、發燒、畏寒或不明感染、噁心、食慾不佳,應儘速就醫,及早檢查與處置,可有效避免膽道感染或敗血症等嚴重併發症。
更多新聞推薦