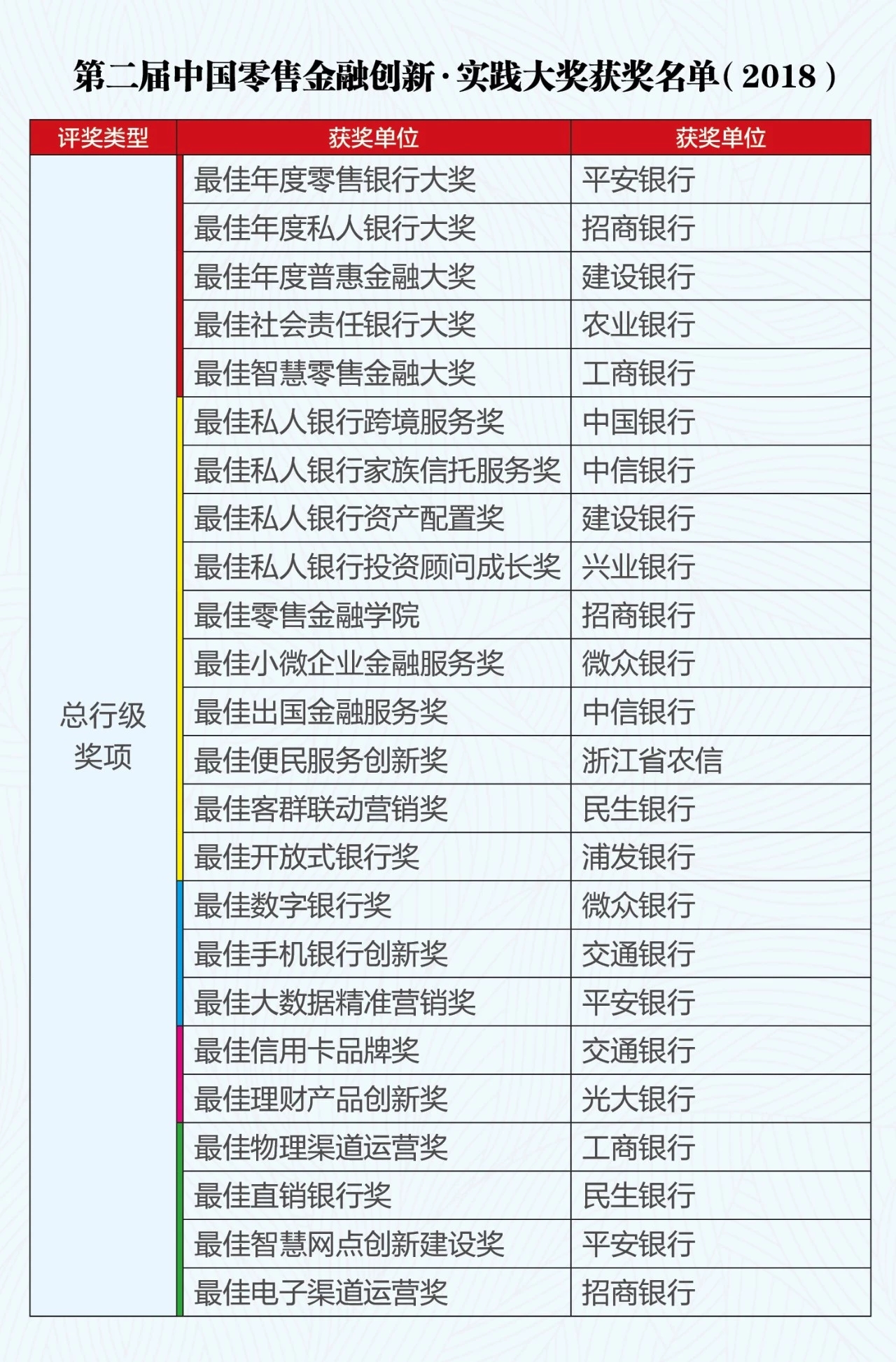
尋夢新聞LINE@每日推播熱門推薦文章,趣聞不漏接❤️
Trias聯合「北大軟微-八分量協同創新實驗室」定期舉辦技術沙龍。該實驗室成立於去年9月份,以可信計算、區塊鏈等作為主要研究方向,致力於推動智能互聯新時代下的人機互信問題的解決。針對沙龍具體細節問題,我們將推出由實驗室教授、博士生主筆撰寫的系列文章。本期文章由北京大學的博士生張曉磊撰寫。
以下是張博士帶來的分享:
最近非常火的區塊鏈技術對於大家來說應該並不陌生。但是很多人只是了解區塊鏈技術的一些概念,對其底層的一些技術做到原理可能不是很了解。這篇文章會向你介紹區塊鏈底層採用的通信網路技術及其網路中節點間的通信協議。
區塊鏈的底層網路技術採用的是peer-to-peer網路,簡稱P2P網路。這是一種分布式網路通信技術,又稱 「對等網路」。與傳統的客戶端/服務器端(client/server, C/S)結構不同的是,在P2P網路中各個節點之間沒有主從之分,地位都是對等的,每一個節點既可以是服務器端也可以是客戶端。
P2P網路根據其路由查詢結構可以分為四種類型,分別是集中式、純分布式、混合式和結構化模型。這四種類型也代表著P2P網路技術的四個發展階段。
其中,比特幣採用的身世混合式,而現今公鏈大多採用的是結構化類型。在結構化網路的具體做到上,大都採用DHT(Distributed Hash Table, 分布式哈希表)算法的思想。基於DHT算法思想的具體做到方案有Chord、Pastry、CAN和Kademlia等算法。其中Kademlia算法是以太坊網路使用的算法,本文中我們將對其進行詳細描述。
比特幣網路
區塊鏈技術最早的使用是在比特幣中,前面我們也說到了,比特幣網路採用的結構是混合式網路。在比特幣網路中的節點有四個功能,分別是:錢包、挖礦、區塊鏈數據庫、網路路由。這四大功能並不是比特幣中所有節點都包含,不同類型的節點只包含部分功能,只有比特幣核心(Bitcoin Core)節點才會包含所有的這四個功能。

圖 1.全節點示意圖,其中Wallet表示錢包功能、Miner表示挖礦功能、Full Blockchain表示完整的區塊鏈數據庫、Network表示路由功能[1]
依據其所包含的功能不同節點的類型也不同,但是所有的節點都會包含路由功能,因為所有的節點都要參與校驗和廣播(傳播交易和區塊信息),並且發現和維持與其他節點的連接。除此之外,一些節點包含完整的區塊鏈數據庫,數據庫中包含所有的交易數據,這類節點被稱為 「全節點(Full Block Chain Node)」。全節點可以獨立自主的校驗所有交易。
還有一些節點只包含了部分區塊鏈數據,一般只包含區塊頭,這類節點通過「簡易支付驗證(SPV)」的方式完成對交易的驗證,該類節點被稱為「SPV節點」或者「輕量級節點」。礦工節點是通過在特殊的設備上面運行工作量證明(proof-of-work)算法的方式(挖礦)來相互競爭的生成新的區塊。
礦工節點中有些節點是全節點,被稱為「獨立礦工(Solo Miner)」,另外一些礦工節點則需要依賴礦池服務器維護的全節點進行挖礦工作,這類礦工被稱為「礦池礦工(Pool Miner)」,礦池礦工與礦池服務器形成礦池(Mining Pool),這是一個局部的集中式網路。它們之間通過特殊的礦池協議進行通信。
目前主流的礦池協議是Stratum協議。錢包功能一般是幫助用戶來查看自己的餘額、管理公私鑰對以及發起交易,在比特幣網路中除了比特幣核心錢包是全節點之外,大部分的錢包都是輕量級節點。
一個包含了各種節點,不同節點之間運行著比特幣主網路協議、Stratum網路協議和其他礦池網路協議的比特幣擴展網路如下圖所示:

圖 2.比特幣擴展網路示意圖 [2]
以太坊網路
以太坊作為新一代以區塊鏈作為底層技術的平台,在很多方面與比特幣很類似,其節點同樣具有錢包、挖礦、區塊鏈數據庫和路由四大功能、同樣也是由於節點包含不同的功能而將其分為不同的類型、同樣除了主網路之外還存在著許多的擴展網路。但是,與比特幣不同的是其底層網路結構,比特幣主網的P2P網路是無結構的,而以太坊使用P2P網路是有結構的,其P2P網路通過Kademlia(簡稱Kad)算法來做到。Kad算法作為DHT(分布式哈希表)技術的一種,可以在分布式環境下做到快速而又準確的路由和定位數據的功能。下面我們著重講一下Kad算法的基本內容。
Kademlia算法
Kad算法作為一種分布式數據存儲及路由發現算法,因其具有簡單性、靈活性、安全性的特點,被以太坊用作底層P2P網路的主要算法。下面我們將通過一個例子來形象的說明Kad算法的主要內容及其運行過程。
問題描述與場景假設
我們假設這樣一個場景:有若干圖書供同學們共享,為了公平起見每個人保存其中的幾本,如果你想要看其他的書,就需要向保存這本書的學生來借。那麼問題是我們怎麼能找到保存著這本書的學生呢?如果一個一個去問的話,效率顯然極低。將這個問題放到P2P網路中,就是一個節點如果需要某個資源,它怎麼獲取這個資源?怎麼快速地找到存儲該資源的節點?
節點信息
就像我們在學校中對每一個學生有著唯一的標識一樣,在Kad算法中給每個節點設置了幾個屬性來唯一標識一個節點,分別是:節點ID、IP地址、端口號。對應到我們的例子中就是:節點ID對應著學生的學號,IP地址和端口號對應著學生的聯繫方式(電話號或者家庭住址)。
每個學生(節點)手中有以下信息:
· 分配給其的圖書信息(分配到節點上的資源信息)。這里的信息指的是書名的hash值和書本的內容(對於節點資源中理解為資源的索引和資源的內容,將其以<key, value>的形式存儲在節點上)。
· 一個通訊錄,里面存儲著若干條記錄,每條記錄是某本書的書名hash值和存儲這本書的學生的學號和聯繫方式(一張路由表,每個路由項里面存儲著某個資源的索引和存儲該資源的節點信息,在Kad算法中,這個路由表稱為「K-bucket」,後面我們將對「K-bucket」進行詳細的介紹)。值得注意的是,這里每個學生存儲的只是一部分同學的聯繫方式(節點的路由表中只存儲著一部分節點的信息)。
資源存儲及查找
那麼問題來了,我們應該如何將書本分發給各個同學呢(將資源分配到節點上)?在Kad算法中它是這樣做的:將每本書的書名做一個hash計算,將得到書名的hash值作為書本的索引,然後在書本的索引與節點ID之間建立一個映射。如果一本書的hash值為000110,那麼這本書就會被分配給學號為000110的學生。(這就要求hash算法的值域和節點ID的取值範圍是一致的,在以太坊中,節點ID的是256位二進制。因為以太坊中採用的hash算法是sha-3,結果長度為256位二進制)
那這里就會有人問了,萬一某一個學生聯繫不上了(節點下線或者退出網路)那麼豈不是他保存的書(資源)就沒有辦法獲得了?為了解決這個問題,Kad算法採取的方法是將這本書的副本存儲在學號與000110最接近的若干位學生手里,這樣學號為000111、000101等若干學生手里也會有這本書(在節點中就是將相同的資源存儲在與目標節點ID最接近的幾個節點上)。當你需要找到這本書的時候,你只要對書名進行hash,就可以知道你要找的是哪一(幾)個學生的聯繫方式了(對於節點中資源來說,我們只需要計算得到資源索引就可以知道要找哪一個或者哪幾個節點了)。
節點定位
我們已經知道應該找哪一(幾)個學生來獲得圖書,那麼接下來的問題就是怎麼找到他們的聯繫方式。這里我們對Kad算法中的路由表–「K-bucket」進行介紹,作為一張路由表,K-bucket里面存儲的就是節點的路由信息,但是和一般的路由表不一樣的是,在K-bucket中是通過距離來對節點進行分類的,如圖3所示。這里提到了節點間的距離問題。我們先來看下在kad算法中是如何計算兩節點間的距離的。
Kad算法中節點間的距離是邏輯距離,這個邏輯距離是通過對節點ID進行異或來計算的。目標節點到本節點的距離在[2(i-1), 2i)範圍內時,該節點被歸為 「K-bucket i」。比如節點ID為000111的節點與節點ID為000110、000011的節點之間的距離計算為:000111 Å 000110 = 000001(十進制1)、000111 Å 000011 = 000100(十進制4)。那麼按照上述的算法就是,在節點ID為000111的K-bucket中,節點ID為000110的節點被分配到「K-bucket 1」中、節點ID為000011的節點被分配到「K-bucket 3」中。

圖3.K-bucket 示意圖
其實這種使用異或來計算距離的方式,相當於將整個網路拓撲組織成一顆二叉前綴樹如圖4所示。這里所有的節點都分布在二叉前綴樹的葉子節點上,這種組織形式相當於按其節點ID的每一位對節點距離進行分類。以圖中的編號為110的節點為例,因為節點000、001、010是第三位(從右往左數)與110不同,因此這三個節點就被分配到110 的「K-bucket 3」中,節點ID為100、101的節點因為是第二位(從右往左數)與110不同,因此這兩個節點就被分配到110 的「K-bucket 2」中,最後節點ID為111的節點因為是第一位(從右往左數)與110 不同,因此它就被安排到110的「K-bucket 1」中。

圖 4.表示網路拓撲結構的二叉前綴樹[3]
回到以太坊中,在前面已經提到了每個節點ID是256位長,因此在以太坊中的節點的K-bucket大小分配為256行每行最多存儲16節點的路由信息。
通過前面的內容我們已經知道了找到另一個學生聯繫方式(節點間的距離計算)的方法以及每個學生存儲的通訊錄是怎樣的的結構(節點中K-bucket的存儲結構)。那我們就來找一本書來看一下在Kad算法中查找某一確定節點的方式是怎樣的。
學號為000111 的A同學想要找一本名叫《西遊記》的書(節點ID為000111的節點想要找到某一個特定的資源),他首先通過對書名計算hash值來得到這本書的索引(得到資源的索引),經過計算得到《西遊記》的hash值為001011,那麼他就知道這本書被保存在學號為001011的B學生手里。接著,A同學就計算與這個學生的距離來查找他的通訊錄(節點計算目標節點與自己的距離,在K-bucket中查找否有目標節點),經過異或計算:000111 Å 001011 = 001100(十進制 12),經過計算發現這個距離12位於[23, 24)這個區間中,因此A同學就去他的通訊錄的第4行去找有沒有B同學的聯繫方式:
· 如果有–就直接聯繫B向他借書;
· 如果沒有–就隨便找一個也在第4行的C同學與其取得聯繫,讓C同學在自己的通訊錄中使用同樣的方法找一下是否有B同學的聯繫方式。這里這樣做的原因是C同學學號的第四位(從右往左數)一定與B同學學號的第四位一樣,因此邏輯上C同學距離B同學的距離一定比A同學距離B同學要近。那麼就會出現兩種情況:
–如果C同學有B同學聯繫方式,那麼他就將B同學的聯繫方式告訴A同學。
–如果沒有,那麼C同學就將與B同學在通訊錄的同一行的另一位D同學的聯繫方式告訴A同學,之後A同學在將D同學的聯繫方式存儲起來後與D同學聯繫,進行下一步查找。以此遞歸下去直到找到B同學為止。
這時有人就會問,上面提到一本書不是不僅僅保存在一個同學手里嗎?我們為什麼非要就找這一個同學?這是因為上面我們描述的是通過一個確定的節點ID來查找另一個節點的過程,對應著Kad算法中的FIND_NODE指令,當然問題中提到的做法是Kad算法中的另一個指令FIND_VALUE。這個指令是通過資源的索引值來搜尋指定的資源,其操作過程與FIND_NODE非常類似,最後終止的條件就是有某一個節點返回了我們要查找的資源數據即可。
值得一提的是,K-bucket的這種更新機制是只有老的節點失效後,才會將新節點加入到K-bucket中,這樣做會保證在線時間長的節點會有更大概率被保留,增加了網路的穩定性,避免網路中節點因大量新節點加入更新K-bucket而出現拒絕服務的情況。
總結
以上就是本文分享的所有內容,我們先介紹了P2P網路的基本知識,然後介紹了比特幣網路的相關內容,最後著重介紹了以太坊網路中Kademlia算法的相關內容。
Trias中的goosip協議與Kad算法比較相關。相對於我們今天講的Kad算法來說,二者對應的層面是不同的,Kad算法更接近底層,而goosip協議偏高層一點,底層Kad算法在開始將節點的路由表(K-bucket)創建好為goosip協議做準備,當goosip協議挑選a個節點進行廣播同步信息時,Kad算法可以保證這a個節點都收到消息並將其存儲下來。
引用
[1] 圖片1引自《精通比特幣》(第二版)
[2] 圖片2引自《精通比特幣》(第二版)
[3] 圖片4引自 wiki 百科:https://en.wikipedia.org/wiki/Kademlia