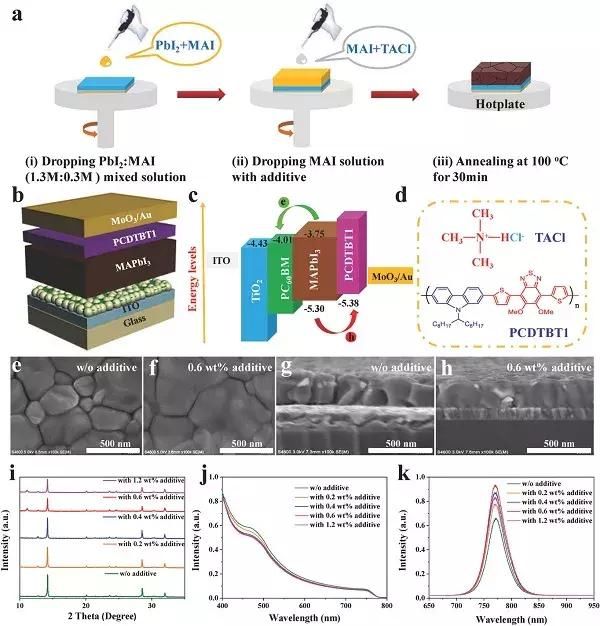
尋夢新聞LINE@每日推播熱門推薦文章,趣聞不漏接❤️
選自arXiv
作者:John Olafenwa
參與:Geek AI、路
第 35 屆國際機器學習會議(ICML 2018)正在瑞典斯德哥爾摩舉行。人工智能創業公司 Petuum 共有 5 篇論文入選,包含門控規劃網路、變換自回歸網路和無限可微分蒙特卡羅可能器等研究。本文將摘要介紹其中一篇論文《Nonoverlap-Promoting Variable Selection》,其中提出了一種有效的新型正則化方法,能夠促進變量選擇中的非重疊效應。
在評估模型質量的各種指標中,有兩個比較常用:(1)在未曾見過的數據上的預測準確度;(2)對模型的解釋。對於(2),科學家更喜歡更簡單的模型,因為響應和協變量之間的關係更清晰。當預測量(predictor)的數量很大時,簡約性問題就會變得尤其重要。當預測量的數量很大時,我們往往希望確定出一個能展現最強效果的小子集。
為了能在選擇出重要因素的一個子集的同時得到準確的預測,研究者常常使用基於正則化的變量選擇方法。其中最值得提及的是 L1 正則化(Tibshirani, 1996),這能促進模型系數變得稀疏。其變體包括 L1/L2 范數(Yuan & Lin, 2006),其中引入了組稀疏效應(group sparsity effect)和彈性網路(elastic net)(Zou & Hastie, 2005),這能強烈地促進大量預測量中互相相關的預測量共同進入或離開模型。
在很多機器學習問題中,都可以基於同一個協變量集預測出多種響應。比如,在多任務分類任務中,具有 m 個類別的分類器建立在一個共享的特徵集之上,而且每個分類器都有一個類別特定的系數向量。在主題建模任務(Blei et al., 2003)中,可以在同一個詞匯庫上學習到多個主題,並且每個主題都有一個基於詞的特有多項式分布。不同的響應與協變量的不同子集相關。比如,教育主題會與「學生」、「大學」和「教授」等詞相關,而政治主題則會與「政府」、「總統」和「選舉」等詞相關。為了在執行變量選擇時考慮到不同響應之間的差異,我們希望為不同響應選出的變量之間的重疊更少。
這個問題可用以下數學形式描述。設有 m 個響應共享 d 個協變量。每個響應都有一個特定的 d 維權重向量 w,其中每一維都對應於一個協變量。設為 w 的支撐集,索引了一個響應的所選變量。對於任意兩個響應 i 和 j,我們希望它們的所選變量 s(wi) 和 s(wj) 有更少的重疊,其重疊度的衡量方式為
。為了達到這個效果,我們提出了一種正則化器(regularizer),可同時促進不同的權重向量接近正交且每個向量變得稀疏,這能聯合促使向量的支撐集的重疊更小。我們也通過實驗表明:最小化該正則化器能夠降低所選變量之間的重疊。
這項研究工作的主要貢獻包括:
方法
在這一節,我們提出了一種非重疊促進型正則化器,並將其應用在了 4 種機器學習模型上。
1 非重疊促進型正則化
我們假設模型有 m 個響應,其中每一個都使用一個權重向量進行了參數化。對於向量 w,其支撐集 s(w) 定義為——w 中非零項的索引。而且這個支撐集包含所選變量的索引。我們首先定義一個分數來衡量兩個響應的所選變量之間的重疊程度:

這是支撐集的 Jaccard 指數。越小,則兩個所選變量的集合之間的重疊程度就越低。對於 m 個變量集,重疊分數則定義為各對分數之和:

這個分數函數不是平滑的,如果被用作正則化器會很難優化。我們則根據提出了一個平滑的函數,並且可以做到與 o(W) 相近的效果。其基本思想是:為了促進重疊較小,我們可以讓(1)每個向量有少量非零項,(2)向量之間的支撐集的交集較小。為了做到(1),我們使用一個 L1 正則化器來促使向量變得稀疏。為了做到(2),我們促使向量接近正交狀態。對於兩個稀疏向量,如果它們接近正交,那麼它們的支撐集將會落在不同的位置。這樣能讓支撐集的交集較小。
我們遵循了(Xie et al., 2017b)提出的方法來促進正交性。為了讓兩個向量 wi 和 wj 接近正交,可讓它們的 L2 范數、接近 1,讓它們的內積接近 0。基於此,就可通過促使這些向量的 Gram 矩陣接近於一個單位矩陣 I 來促進一組向量之間的正交性。因為 G 和 I 各自的對角線上沒有了和 0,而分別是
和 1,所以要讓 G 接近 I,本質上就是讓接近 0,讓
接近 1。由此,就促使 wi 和 wj 接近正交了。(Xie et al., 2017b)提出的一種用於衡量兩個矩陣之間的「接近度」的方法是使用對數行列式散度(LDD:log-determinant divergence)(Kulis et al., 2009)。兩個 m×m 正定矩陣 X 和 Y 之間的 LDD 定義為,其中 tr(·) 表示矩陣的跡。G 和 I 之間的接近度可以通過讓它們的 LDD更小來得到。
將正交促進型 LDD 正則化器與稀疏度促進型 L1 正則化器組合到一起,我們就得到了以下 LDD-L1 正則化器:

其中 γ 是這兩個正則化器之間的權衡參數。我們的實驗已經驗證,這種正則化器可以有效地促進非重疊。對(3)式和(2)式之間的關係的形式分析留待未來研究。值得提及的是,單獨使用 L1 或 LDD 都不足以降低重疊。如圖 1 所示,其中 (a) 是僅使用了 L1 的情況——盡管這兩個向量是稀疏的,但它們的支撐集完全重疊。在 (b) 中僅使用了 LDD——盡管這兩個向量非常接近正交,但因為它們是密集的,所以它們的支撐集完全重疊。(c) 中則使用了 LDD-L1 正則化器,這兩個向量是稀疏的且接近正交。因此,它們的支撐集不重疊。

圖 1:(a) 使用 L1 正則化的情況,向量是稀疏的但它們的支撐集重疊;(b) 使用 LDD 正則化的情況,向量是正交的但它們的支撐集重疊;(c) 使用 LDD-L1 正則化的情況,向量稀疏且互相正交,它們的支撐集不重疊。
2 案例研究
我們將 LDD-L1 正則化器應用在了 4 種機器學習模型上:
3 算法
對於 LDD-L1 正則化的 MLR、NN 和 DML 問題,我們使用近端梯度下降(Parikh & Boyd, 2014)求解它們。這種近端操作針對的是 LDD-L1 中的 L1 正則化器。算法會迭代地執行以下三個步驟,直到收斂:(1)計算的梯度,其中 L(W) 是未正則化的機器學習模型的損失函數,是 LDD-L1 中的 LDD 正則化器;(2)執行 W 的梯度下降更新;(3)將 L1 正則化器的近端算子應用於 W。

算法 1:求解 LDD-L1-SC 問題的算法
實驗

表 2:在 20-News 和 RCV1 的測試集上的分類準確度,以及訓練準確度和測試準確度之間的差距

表 4:在 PTB 測試集上的詞級困惑度

表 5:在 CIFAR-10 測試集上的分類誤差(%)
論文:非重疊促進型變量選擇(Nonoverlap-Promoting Variable Selection)
論文地址:http://proceedings.mlr.press/v80/xie18b/xie18b.pdf
變量選擇是機器學習(ML)領域內的一個經典問題,在尋找重要的解釋因素以及提升機器學習模型的泛化能力和可解釋性方面有廣泛的應用。在這篇論文中,我們研究了要基於同一個協變量集預測多個響應的模型的變量選擇。因為每個響應都與一個特定協變量子集有關,所以我們希望不同響應的所選變量之間有較小的重疊。我們提出了一種能同時促進正交性和稀疏性的正則化器,這兩者能共同帶來降低重疊的效果。我們將這種正則化器應用到了 4 種模型實例上,並開發了求解正則化問題的有效算法。我們對新提出的正則化器可以降低泛化誤差的原因進行了形式分析。我們在仿真研究和真實世界數據集上都進行了實驗,結果表明我們提出的正則化器在選擇更少重疊的變量和提升泛化性能上是有效的。
本文為機器之心編譯,轉載請聯繫原作者獲得授權。